In this post, I’ll be exploring all about Keras, the GloVe word embedding, deep learning and XGBoost (see the full code). This is a playground, nothing new, since I’ve pulled about 75% of this from all over the web. I’ll be dropping references here and there so you can also enjoy your own playground.
That said, let’s get started! First off, some boilerplate code.
“The Python Preamble”
In this section, most code is pulled from the Keras project over in Github.
https://github.com/fchollet/keras/tree/master/examples
import os
import numpy as np
np.random.seed(1337)
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.utils.np_utils import to_categorical
from keras.layers import Dense, Input, Flatten
from keras.layers import Conv1D, MaxPooling1D, Embedding
from keras.models import Model
import sys
%pylab inline
BASE_DIR = '.'
GLOVE_DIR = BASE_DIR + '/glove/'
MAX_SEQUENCE_LENGTH = 1000
MAX_NB_WORDS = 20000
EMBEDDING_DIM = 100
VALIDATION_SPLIT = 0.2
Introducing GloVe and Word Embeddings
Global Vectors for Word Representation (GloVe) is an unsupervised learning algorithm for obtaining vector representations for words. It’s basically computing co-word occurrences statistics from a large corpus. This is different compared to Word2Vec skip-gram or CBOW models, which is trained using model predictions of the current word given a window of surrounding words.
Ultimately though, GloVe and Word2Vec is concerned with achieving word embeddings. The goal is to find a high dimensional vector representation for each word. This is different from BOW models which can result in a very sparse matrix with no attractive mathematical properties other than classification in machine learning. For word embeddings, practitioners can create structures and reason on word distances on this high dimensional space. We’ll find for example, the word “cat” is close to other feline entities such as “tiger”, “kitty” and “lion”. We’ll also see that “cat” is farther than “dog” as compared to “kitty”. Mathematically:

But, we can achieve something like this!

Thus, we can represent differences:
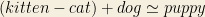
Anyway, these are just fun properties. The most important thing for word embeddings is that even if the new corpora is small, more concepts can be brought to it from the pre-trained word embeddings. For example, if the new corpora mentions “economics”, its word vector contains properties related to broad ideas like “academia” and “social sciences”, as well as narrower concepts such as “supply” and “demand”. This can somehow be called transfer learning, an attractive concept from deep learning.
You’ll find a great tutorial for word embeddings in the Udacity course on NLP and deep learning.
https://www.udacity.com/course/deep-learning–ud730
Stanford has a good site for GloVe:
http://nlp.stanford.edu/projects/glove/
GLoVe, can be downloaded here:
http://nlp.stanford.edu/data/glove.6B.zip
Preprocessing
Next, we’ll be using GloVe to transform our words into high dimensional vectors.
print 'Indexing word vectors.'
embeddings_index = {}
f = open(os.path.join(GLOVE_DIR, 'glove.6B.100d.txt'))
for line in f:
values = line.split()
word = values[0]
coefs = np.asarray(values[1:], dtype='float32')
embeddings_index[word] = coefs
f.close()
print 'Found {} word vectors.'.format(len(embeddings_index))
from sklearn.datasets import fetch_20newsgroups
newsgroups_trainval = fetch_20newsgroups(subset='train')
print 'Processing corpora'
texts = [article.encode('latin-1') for article in newsgroups_trainval.data]
labels_index = dict(zip(range(len(newsgroups_trainval.target_names)), newsgroups_trainval.target_names))
labels = newsgroups_trainval.target
print 'Found {} texts'.format(len(texts))
# quantize the text samples to a 2D integer tensor
# note that the values here are ultimately indexes to the actual words
tokenizer = Tokenizer(nb_words=MAX_NB_WORDS)
tokenizer.fit_on_texts(texts)
sequences = tokenizer.texts_to_sequences(texts)
word_index = tokenizer.word_index
print 'Found {} unique tokens.'.format(len(word_index))
data = pad_sequences(sequences, maxlen=MAX_SEQUENCE_LENGTH)
sequences = None
texts = None
labels = to_categorical(np.asarray(labels))
print 'Shape of data tensor: ', data.shape
print 'Shape of label tensor: ', labels.shape
indices = np.arange(data.shape[0])
np.random.shuffle(indices)
data = data[indices]
labels = labels[indices]
nb_validation_samples = int(VALIDATION_SPLIT * data.shape[0])
X_train = data[:-nb_validation_samples]
y_train = labels[:-nb_validation_samples]
X_val = data[-nb_validation_samples:]
y_val = labels[-nb_validation_samples:]
dict(word_index.items()[:10])
print 'Preparing embedding matrix.'
nb_words = min(MAX_NB_WORDS, len(word_index))
embedding_matrix = np.zeros((nb_words + 1, EMBEDDING_DIM))
# word index is sorted by rank of the word
for word, i in word_index.items():
# skip the word if the rank is above MAX_NB_WORDS
# resulting in a matrix of exactly [MAX_NB_WORDS + 1, EMBEDDING_DIM]
if i > MAX_NB_WORDS:
continue
embedding_vector = embeddings_index.get(word)
if embedding_vector is not None:
embedding_matrix[i] = embedding_vector
# if word is not found in the embeddings index, then it's all 0.
# load pre-trained word embeddings into an Embedding layer
# note that we set trainable = False as to keep the embeddings fixed
embedding_layer = Embedding(nb_words + 1, EMBEDDING_DIM, weights=[embedding_matrix],
input_length= MAX_SEQUENCE_LENGTH,
trainable=False)
Classification using Convolutional Neural Nets
Now, we start using Keras for our CNN. This is a very basic CNN model, using a single stride architecture. In more advanced CNNs, one can have multiple strides and concatenation layer combined with max pool layers.
from keras.layers import Dropout
print 'Preparing model.'
sequence_input = Input(shape=(MAX_SEQUENCE_LENGTH,), dtype='int32')
embedded_sequences = embedding_layer(sequence_input)
x = Conv1D(128, 5, activation='relu')(embedded_sequences)
x = MaxPooling1D(5)(x)
x = Conv1D(256, 5, activation='relu')(x)
x = MaxPooling1D(5)(x)
x = Conv1D(512, 5, activation='relu')(x)
x = Flatten()(x)
x = Dense(1024, activation='relu')(x)
preds = Dense(len(labels_index), activation='softmax')(x)
from keras.callbacks import History, EarlyStopping, ModelCheckpoint
history = History()
early = EarlyStopping(patience=5)
checkpoint = ModelCheckpoint("model.weights.checkpoint", save_best_only=True,
save_weights_only=True, verbose=1)
callbacks_list =[history, early, checkpoint]
print 'Training model.'
model = Model(sequence_input, preds)
model.compile(loss='categorical_crossentropy', optimizer='rmsprop', metrics=['acc'])
model.fit(X_train, y_train, validation_data = (X_val, y_val), nb_epoch=20, batch_size=128,
callbacks = callbacks_list)
model.summary()
model.load_weights("model.weights.checkpoint")
Network performance
Pulled from scikit learn’s pretty confusion matrix.
http://scikit-learn.org/stable/auto_examples/model_selection/plot_confusion_matrix.html
import itertools
def plot_confusion_matrix(cm, classes,
normalize=False,
title='Confusion matrix',
cmap=plt.cm.Blues, figsize=(15,15)):
"""
This function prints and plots the confusion matrix.
Normalization can be applied by setting `normalize=True`.
"""
plt.figure(figsize=figsize)
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45)
plt.yticks(tick_marks, classes)
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, cm[i, j],
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
from sklearn import metrics
preds = model.predict(X_val)
preds = np.argmax(preds, axis=1)
y_val_actual = np.argmax(y_val, axis=1)
print "Accuracy: ", metrics.accuracy_score(y_val_actual, preds)
print "Classification report: "
print metrics.classification_report(y_val_actual, preds)
conf_mat = metrics.confusion_matrix(y_val_actual, preds)
plot_confusion_matrix(conf_mat, newsgroups_trainval.target_names)
# then let's save the model for future use
model.save("keras_nlp.convnet.model")
Build features for other classifiers
http://nadbordrozd.github.io/blog/2016/05/20/text-classification-with-word2vec/
So much for CNNs. We can also transform our words embeddings to features. In this case, the linked post above highlights averaging word vectors for an entire document. Much information is lost in this case, however, but it will be a good starting point for other techniques such as Doc2Vec.
from sklearn.feature_extraction.text import TfidfVectorizer
from collections import defaultdict
class TfidfEmbeddingVectorizer(object):
def __init__(self, word2vec):
self.word2vec = word2vec
self.word2weight = None
self.dim = len(word2vec.itervalues().next())
def fit(self, X, y):
tfidf = TfidfVectorizer(analyzer=lambda x: x)
tfidf.fit(X)
# if a word was never seen - it must be at least as infrequent
# as any of the known words - so the default idf is the max of
# known idf's
max_idf = max(tfidf.idf_)
self.word2weight = defaultdict(
lambda: max_idf,
[(w, tfidf.idf_[i]) for w, i in tfidf.vocabulary_.items()])
return self
def transform(self, X):
return np.array([
np.mean([self.word2vec[w] * self.word2weight[w]
for w in words if w in self.word2vec] or
[np.zeros(self.dim)], axis=0)
for words in X
])
# I'll be repeating the above preprocessing here.
texts = [article.encode('latin-1') for article in newsgroups_trainval.data]
labels = newsgroups_trainval.target
indices = np.arange(len(texts))
np.random.shuffle(indices)
texts = [texts[i] for i in indices]
labels = labels[indices]
nb_validation_samples = int((1-VALIDATION_SPLIT) * len(texts))
text_train = texts[:nb_validation_samples]
text_val = texts[nb_validation_samples:]
y_train = labels[:nb_validation_samples]
y_val = labels[nb_validation_samples:]
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
vectorizer = Pipeline([('vectorizer', TfidfEmbeddingVectorizer(embeddings_index)),
('standardizer', StandardScaler())])
X_train = vectorizer.fit_transform(text_train)
X_val = vectorizer.transform(text_val)
