I’m absolutely stoked that I’m doing deep learning. I’ve been following this very detailed blog. It’s Daniel Nouri’s solution on the Kaggle competition, Facial Keypoints Detection. The challenge here is to build a model that can predict the positions of facial keypoints like the centers of the eyes, its corners, the nose, the corners of the mouth, etc. What makes this especially interesting is that each person has different relative positions of these facial keypoints, and each photograph is subject to different angles, illumination and expression. If we nail this problem, we can have much more detailed annotation of each person’s face in video and social networks. This can also be a significant leap forward in biometrics and medical diagnosis.

I recently bought an Nvidia GeForce GTX 960. Setting it up in Ubuntu 14.04 is a little pain, but I find this blog and answer useful. I’ve got to say that I’ve panicked when the first time I installed the drivers, my desktop won’t show up. If this happens to you, don’t worry. It’s probably because your Nvidia drivers are of the wrong version. Simply hit the command line and you can repair your box.
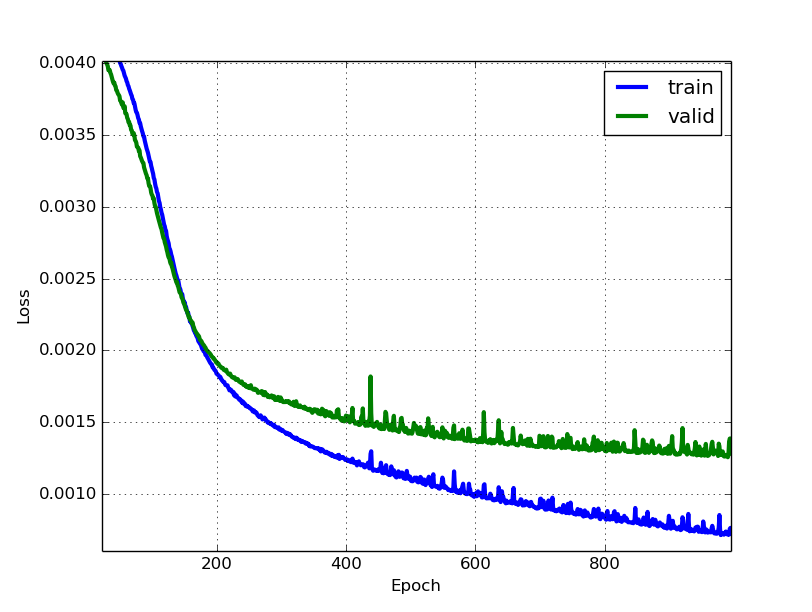
Finally, I started on Daniel’s blog. Deep learning requires heavy processing. For example, for my 13 layer deep network, it has 16,561,502 parameters to optimize. Taking into account our dataset of 7050 examples which has to go through the network 1000 times, we get around 112B operations of mainly multiplications. In a CPU, this takes 200 seconds for a single iteration. Remember we need 1000. For my GPU, it takes 2 seconds for a single iteration. That 100x speedup is very significant. Here’s how the training and the final result looks like.

PS: What is deep learning anyway?
What makes deep learning very interesting is that it could learn the features from the data itself, as opposed to hand-crafted features like SIFT, and ORB. No doubt that you’ve seen Google Brain finding cats in videos everywhere as well as dogs in Google’s Deep Dream. All these abundance of cats and dogs is the result of learning the features directly from the training set — the statistics of the specific task comes into play.
Another interesting thing about deep learning is, being inspired by neural networks, it is similar to how our brains work. Our brains have different areas for different stimuli, and our neurons combine these signals hierarchically. For example, it was way back in 1958 that Hubel and Wiesel discovered some cells in the visual cortex activate in an oriented way given images of lines and basic geometric images. This is called the striate cortex or V1. After this basic stage, these orientations are combined to form edges, then to motifs, patterns, scenes then finally, whole images. This powerful representation allows deep networks to win in almost every computer vision competition in recent years, and it’s expanding to other domains as well.
Not that we’ll awaken some sentient being here. We’re still decades from that. For perspective, a human brain has 100 billion neurons, with potentially 100 trillion connections. Our 16B parameters above is still worm-like compared to that.
