I’ve been tinkering with customer lifetime value modeling the past few days since the Olist dataset in Kaggle went up. In particular, I wanted to explore the tried and tested probabilistic models, BG/NBD and GammaGamma to forecast future purchases and profits. I also wanted to see if the machine learning approach could do well — simply predicting if the customer will make a repeat purchase. These models do the same thing — forecasting customer purchase– albeit in different ways. Perhaps in an update post I can come up with metrics to compare them on equal footing. Anyway, let’s start.
The notebook can be found in Kaggle. Here: https://www.kaggle.com/krsnewwave/clv-with-lifetimes-and-featuretools
Olist is a Brazilian e-commerce site that so generously shared 100k orders on its site from 2016 to 2018. The data can be found here.
What the data looks like
The dataset includes some 95k customers and their orders in the site, which are around 100k unique orders of some 33k products of some 73 categories. It also includes the items’ prices, how much the customers paid, credit card installment payments, and even fright costs associated with the order. It’s data that should look a lot like your own e-commerce company’s data. 😉
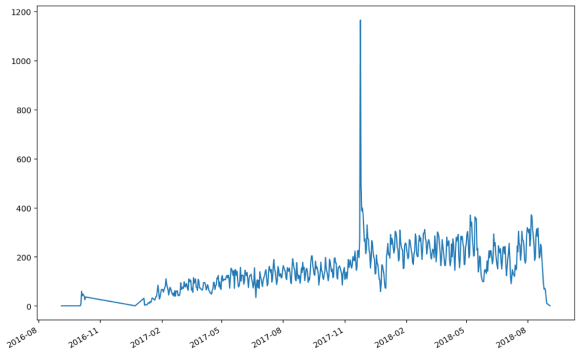
The patterns of purchases seems normal with periodic upticks and a massive spike last December 2017.
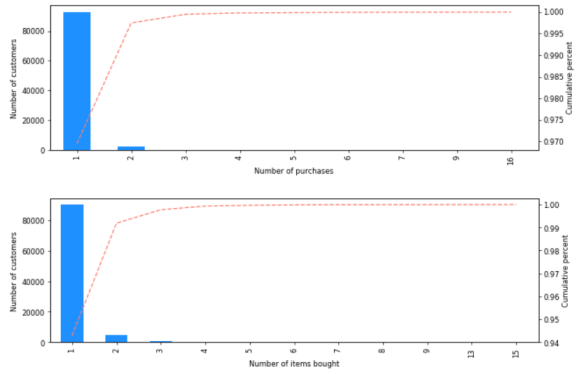
The data shows a very sparse buying pattern per customer, with an average of 1.03 orders and 1.07 items bought per customer.
BG/NBD Model
For the probabilistic models, I’ve used many of the code of this kind gentleman’s kernel. The lifetimes library is very useful in quickly building analyses of this kind. It requires RFM input data, which requires that for each customer, we have info on their most recent purchase, the frequency of their purchases and the total monetary value of their purchases.
The Beta Geometric, Negative Binomial Distribution addresses two problems, 1) the probability of the customer being active or inactive (alive or dead in literature!), and 2) the probability of the number of purchases. (1) is modeled by the beta distribution and (2) is by a Poisson distribution. Each individual or cohort has their own parameters for both of these prediction problems. A simple way to think about it is having a coin and a die to model (1) and (2).
Here are visuals on gauging the performance of our model. It can be seen in both the calibration period (left) and the validation period (right) tests that the model breaks down in trying to predict 4 or more purchases because of the lack of data around this behavior.


The figures below depict frequency in the x axis and recency in the y axis. Frequent and most recent buyers are at the rightmost part of the graph. In the figure (a) below, the expected number of future purchases is very low (0.6) even for the most devoted of buyers (bought recently and bought frequently) in the next 120 days. In (b), even the most devoted of buyers only have some 60% chance of being active. This is due to the very sparse buying pattern of each customer in the data.


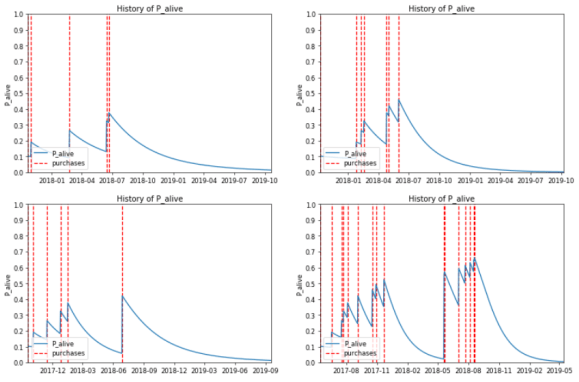
With the model, one can output the ranking of the customers according to the expected number of purchases in the future. This ranking could be used to determine marketing strategies for different segments. Here is the probability of being alive after each buying pattern of the top 4 customers. These top 4 is computed from the highest expected number of purchases up to half a year.
I also tried a GammaGamma model, which takes into account the monetary value of the purchases. However, the predictions were not good, with only a 0.35 correlation on the holdout set. This is maybe because of the sparse nature of the buying patterns. I’ll leave it to a more in-depth study on where precisely the GammaGamma model breaks down vis-a-vis sparsity of purchases.
A wider perspective
From the last section, we abstracted away the nature and number of items bought, the discrete time windows of the purchases, and the context of payments. All of these can be brought to bear on the problem of a repeat purchase. In this section, we’ll use the featuretools library to automatically create features for us.
The process of connecting datasets together is a bit tedious, but the reward is a fully automated feature engineering routine. The entity set will look like the following:
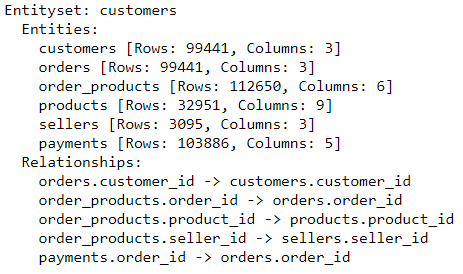
Before transforming the features, we declare a cutoff date and training window. Transactions after the cutoff date will be truncated and a training window period before the cutoff date will form our training set. We shall be predicting if a customer will buy after the cutoff date given all of her transactions before the cutoff date within a training window. Our cutoff date will be July 1, 2018.
The dataset will look like the following with the help of featuretool’s deep feature synthesis (DFS). DFS uses the indexes declared in the relationships to create aggregate and primitive features. For example, we can have something simple like the sum of the payments (depth=1) and also something complex like the customer’s average payment of her order’s max payments (depth=2). Recall that an order can have multiple payments and a customer has multiple orders.
The results of the models are the following:
| Training Window | Model | AUC |
|---|---|---|
| 60 | Truncated SVD – > Logistic Regression | 0.6036 |
| 120 | Truncated SVD – > Logistic Regression | 0.6863 |
| 120 | Random Forest | 0.6841 |
| 120 | Gradient Boosted Trees | 0.6869 |
Not too bad. Increasing the training window significantly boosted our metric, with the more complex models not really contributing too much improvements. As before, we can get the output probabilities of a customer staying as our ranking. We can then create strategies around these ranks.
Lastly, we’ll get into the most important features. Getting the feature importance of random forests and gradient boosted trees through the default way is trivial — the mean decrease in Gini across all trees. I’ll leave it up to the reader to do permutation importance through sampling.

Barring the customer’s cities (trees are biased towards categoricals with many levels), the results are understandable. Customers that bought in the first half of 2018 is likely to buy again in the next half. Customers who bought many orders and have many payments (credit card installments) are likely to buy again. Cool.
Thanks for reading.
