Leveling up Training: NVTabular and PyTorch Lightning
I’m going to use NVTabular with PyTorch Lightning to train a wide and deep recommender model on MovieLens 25M. It’s quite a chimera implementation as you shall see.
In my last post, I tried to run NVIDIA Merlin models using free instances on the web. That did not go so well. But the value of using the GPU for the data engineering and data loading parts is very attractive. In this post, I’m going to use NVTabular with PyTorch Lightning to train a wide and deep recommender model on MovieLens 25M.
For the code, you may check my Kaggle notebook. We have quite the chimera for this implementation as listed below:
The dataset I used is MovieLens 25M. It has 25 million ratings and one million tag applications applied to 62,000 movies by 162,000 users.
Cool? Let’s start!
Data Processing with NVTabular
There are several advantages to using NVTabular. You can use datasets that are larger than memory (it uses dask), and all processing can be done in the GPU. Also, the framework uses DAGs, which are conceptually familiar to most engineers. Our operations will be defined using these DAGs.
We will first define our workflow. First, we’re going to use implicit ratings where 1 is a rating of 4 and 5. Second, we’ll be converting the genres column into a multi-hot categorical feature. Third, we’ll be joining the ratings and the genres tables. Note that the >> is overloaded and behaves just like a pipe. If you run this cell, a DAG will appear.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
You may find the >> operations on lists strange and may take some getting used to. Note also that the actual datasets aren’t defined yet. We will need to define a Dataset, which we will transform using the above Workflow. A Dataset is an abstraction to use chunks of the dataset under the hood. The Workflow will then compute statistics and other information from the Dataset.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
If you run the above snippet, then you will have two resulting output directories. The first, train, will contain parquet files, the schema, and other metadata about your dataset. The second, workflow, will contain the computed statistics, categoricals, etc.
To use the datasets and workflows in training the model, you will use iterators and data loaders. It looks like the following.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Wide and Deep Networks with NVTabular, TorchFM, and PyTorch
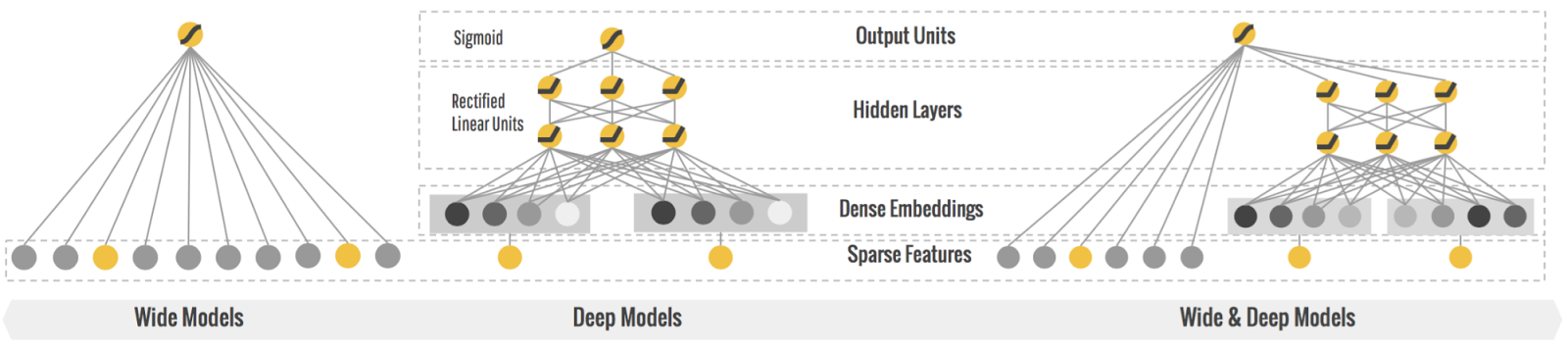
The model we’re using is a wide and deep network which was first used in Google Play. The wide features are the user and item embeddings. For the deep features, we pass the users, items, and item feature embeddings to successively fully connected layers. I’m modifying the genres variable to use multi-hot encodings, which if you look under the hood, is summing together embeddings of the individual categorical values.
See Image 1 for a visual representation from the original authors.
Image 1. Wide and Deep Network.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
To train our model, we define a single training step. This is required by PyTorch Lightning.
First, the data loader from NVTabular outputs a dictionary containing the batch of inputs. In this example, we are handling only categorical values, but this transform step can handle continuous values as well. The output is a tuple of categoricals and continuous variables, plus the label.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Secondly, we define the training step and evaluation steps which uses the transform function above.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
I’m omitting the forward step since it is simply a matter of inputting the categorical and continuous variables to the correct layers, concatenating the wide and deep components of the model, and adding a sigmoid head.
Training with Optuna, PyTorch Lightning, and CometML
With everything defined properly, it’s time to stitch it all together. Each of the functions here (create_loaders, create_model, and create_trainer) is user-defined. As the name suggests, it simply creates these objects for training.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
I’ve launched only 6 trials for this one. Decent, but more trials can yield better results.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
As you can probably guess, there are a lot of components that had to be stitched together. Building this could be a pain especially when there are multiple projects that probably require the same thing. I recommend creating an in-house framework to distribute this template sustainably.
The next steps could be:
Deploy an inference service through TorchServe.
Create a training-deployment pipeline using Kedro.
Extract top-n user recommendations and store them in a cache server.