
In recent years, momentum is building towards MLOps, an effort to distill an operational mindset in machine learning. For me, MLOps is all about creating sustainability in machine learning. We want to sustain a culture of structure and reproducibility in this fast-paced innovative field. Take this familiar scenario as motivation:
Here’s a use case for you to complete. Can you do it before Friday?
Our intrepid hero cobbles together something successfully. Everyone’s happy. Until a few days after, we put it to production. And then a few weeks after, new data comes in. And then a few months after, a new guy takes over the project.
Can your code hold up to the pressure?
Developing machine learning projects is like fixing server cables. We create a dozen experiments, engineering pipelines, outbound integrations, and monitoring code. We try our best to make our work reproducible, robust, and ready for shipping. Add some team collaboration and you’ve got a big ball of spaghetti. As much as we try, something will give, especially with tight timelines. We do small shortcuts that accrue technical debt and will be more unpleasant over time. In our metaphor, messy wires are a fire hazard, and we want them fixed right away. The data must flow!

Someone figured this out before, right? Turns out, yes, we’re in a time where MLOps has a lot of momentum. There are a dozen of tools and frameworks out there to support MLOps. In the past, I’ve used a combination of in-house self-maintained frameworks and a personal set of engineering standards. If you don’t have the time to create your own framework, then it is good to have a robust scaffolding like Kedro to take care of the foundations for you.
Firing up Kedro
Kedro is an open-source Python project that aims to help ML practitioners create modular, maintainable, and reproducible pipelines. As a rapidly evolving project, it has many integrations with other useful tools like MLFlow, Airflow, and Docker, to name a few. Think of Kedro as the glue to tie your projects together into a common structure, a very important step towards sustainable machine learning. Kedro has amazing documentation, so be sure to check it out.
Starting a kedro project is easy. I’ve written several things in the code block below.
# (1) virtual environment
conda activate kedro-env
pip install kedro kedro-mlflow optuna kedro[pandas] kedro-viz -y
# (2) new project with starter
# put anything, for me, I wrote 'tutorial'
kedro new --starter=pandas-iris
cd tutorial
# (3) fire up git. The starter already has a gitignore file and
# gitkeeps so you can git add things safely after.
git init
# (4) install dependencies. See requirements.in to add more.
kedro install
# (5) run the pipeline. You can also do kedro run --pipeline=[name]
kedro run
- Virtual environments are almost always necessary. Create one, and install kedro.
- Create a kedro project. In this example, I use an official starter project. There are others, linked here. A powerful feature of Kedro is that you can create your own template through cookiecutter. Check this out for your organization’s own standards.
- Create a new git environment — another must for MLOps!
- Install dependencies.
- Run the pipeline.
You’ll see that there are some directories generated for you. This structure is the backbone for any kedro project. The following definitions are pulled from official documentation:
get-started # Parent directory of the template
├── conf # Project configuration files
├── data # Local project data (not committed to version control)
├── docs # Project documentation
├── logs # Project output logs (not committed to version control)
├── notebooks # Project related Jupyter notebooks (can be used for experimental code before moving the code to src)
├── README.md # Project README
├── setup.cfg # Configuration options for `pytest` when doing `kedro test` and for the `isort` utility when doing `kedro lint`
└── src # Project source code
You’ll see a couple of great operational things already baked in, like testing, logging, configuration management, and even a directory for Jupyter notebooks.
The Anatomy of a Kedro Pipeline
For the rest of the post, I’ll be using a dataset pulled from Kaggle, which is for a cross-sell use case in health insurance. If you want my whole code, you can also check out this Github link.
You’ll see later that the data engineering and machine learning work is quite standard but where Kedro really shines is how it can make your pipelines maintainable and frankly, beautiful. Check my pipeline here:

A Kedro pipeline is made up of data sources and nodes. Starting from the top, you see the data sources. You have the option of putting it in Python code, but in my case, I want it in a configuration file, which is key if there are changing locations, credentials, etc. If you have a dozen of datasets, you would want their definitions away from code for a more manageable headspace. In addition, you can manage intermediate tables and outputs in a configuration file so the formats are all abstracted from the code.
# in <root>/conf/base/catalog.yaml
insurance:
type: pandas.CSVDataSet
filepath: data/01_raw/train.csv
layer: raw
model_input_table:
type: pandas.ParquetDataSet
filepath: data/03_primary/model_input_table.pq
layer: primary
xgboost_pipe.clf:
type: kedro_mlflow.io.artifacts.MlflowArtifactDataSet
data_set:
type: kedro_mlflow.io.models.MlflowModelSaverDataSet
flavor: mlflow.sklearn
filepath: data/06_models/xgboost_clf.pickle
# metrics for mlflow
xgboost_pipe.model_metrics:
type: kedro_mlflow.io.metrics.MlflowMetricsDataSet
prefix: metrics
# objects to upload in mlflow
xgboost_pipe.roc_graph:
type: kedro_mlflow.io.artifacts.MlflowArtifactDataSet
data_set:
type: kedro.extras.datasets.matplotlib.MatplotlibWriter
filepath: data/06_models/xgb.roc_plot.png
By the way, there’s a whole section dedicated in the documentation for credential management and referring cloud resources. I’ll keep things local for simplicity.
Kedro Nodes
The nodes are where the action is. Kedro allows for a lot of flexibility. Here, I’m using scikit-learn and XGBoost for the actual modeling bits, but you can also use PySpark, PyTorch, TensorFlow, HuggingFace, anything. In the code below, I have my data engineering code, and my modeling codes (data_science). It’s up to you how you want your project’s stages to look like. For simplicity’s sake, I only have these two.
First, my data engineering code has a single node, where all the preprocessing is done. For more complex datasets, you might include the preprocessing of specific data sources, data validation, and merging.
Secondly, the data_science codes contain the training of models. The output of the data_engineering section will be inserted as inputs to these nodes. How the inputs and outputs are stitched together is defined in the pipelines section.
# in <root>/src/<project>/pipelines/data_engineering/nodes.py
def preprocess(df: pd.DataFrame) -> pd.DataFrame:
"""Preprocesses the data.
Args:
df: Raw data.
Returns:
Preprocessed data
"""
df["Gender"] = df["Gender"] == "Female"
df["Vehicle_Damage"] = df["Vehicle_Damage"] == "Yes"
df["Vehicle_Age"] = ordinal_vehicle_age(df["Vehicle_Age"])
# trim outliers
df["Annual_Premium"] = trim_outliers(df["Annual_Premium"])
# set variables as categoricals
df["Region_Code"] = df["Region_Code"].astype(np.int32)
df["Policy_Sales_Channel"] = df["Policy_Sales_Channel"].astype(np.int32)
df = pd.get_dummies(df, columns=["Region_Code", "Policy_Sales_Channel"],
prefix=["region", "channel"])
logger = logging.getLogger(__name__)
logger.info(f"Column names are: {df.columns.tolist()}")
if np.any(df.isnull()):
logger.info(df.isnull().sum().sort_values()[::-1])
raise ValueError("Has nulls")
else:
return df
# in <root>/src/<project>/pipelines/data_science/nodes.py
def split_data(data: pd.DataFrame, parameters: Dict) -> Tuple:
X = data.drop(columns=["Response"])
y = data["Response"]
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=parameters["test_size"], random_state=parameters["random_state"]
)
return X_train, X_test, y_train, y_test
def fit_rr(X_train: pd.DataFrame, y_train: pd.Series,
X_test: pd.DataFrame, y_test: pd.Series, params: Dict) -> Dict:
rr_clf = RandomForestClassifier(**params)
rr_clf.fit(X_train, y_train)
dict_metrics = evaluate_model(rr_clf, X_test, y_test)
return {"clf": rr_clf, "model_metrics": dict_metrics}
def evaluate_model(clf: BaseEstimator, X_test: pd.DataFrame, y_test: pd.Series):
y_proba = clf.predict_proba(X_test)[:, 1]
y_preds = y_proba > 0.5
ap = average_precision_score(y_test, y_proba)
loss = log_loss(y_test, y_proba)
bal_acc = balanced_accuracy_score(y_test, y_preds)
logger = logging.getLogger(__name__)
logger.info(f"Average precision: {ap}, loss: {loss}, balanced accuracy: {bal_acc}")
return {"average_precision": {"value": ap, "step": 0},
"loss": {"value": loss, "step": 0},
"balanced_accuracy": {"value": bal_acc, "step": 0}}
Here’s an example with Optuna, a platform for hyperparameter optimization. As you’ll see below, you can also use kedro-mlflow to connect Kedro and MLFlow together.
If you’re the type to be really focused on notebooks, then you might be shocked by the number of .py files. Don’t fret! Kedro has capability to turn your jupyter notebooks into nodes.
# in <root>/src/<project>/pipelines/data_science/nodes.py
def rr_objective(X_train: pd.DataFrame, y_train: pd.Series,
X_test: pd.DataFrame, y_test: pd.Series,
trial: optuna.trial):
max_depth = trial.suggest_int("max_depth", 8, 64, log=True)
min_samples_split = trial.suggest_int("min_samples_split", 50, 1000, )
ccp_alpha = trial.suggest_float("ccp_alpha", 0.001, 0.03, log=True)
rr_clf = RandomForestClassifier(max_depth=max_depth,
min_samples_split=min_samples_split,
ccp_alpha=ccp_alpha,
class_weight='balanced_subsample',
verbose=1)
rr_clf.fit(X_train, y_train)
y_proba = rr_clf.predict_proba(X_test)[:, 1]
ap = average_precision_score(y_test, y_proba)
return ap
def fit_rr_ho(X_train: pd.DataFrame, y_train: pd.Series,
X_test: pd.DataFrame, y_test: pd.Series):
study = optuna.create_study(direction="maximize")
fun_rr_object = partial(rr_objective, X_train, y_train, X_test, y_test)
# increase n_trials > 100 for better success
study.optimize(fun_rr_object, n_trials=5)
best_params = study.best_params
mlflow.log_params(best_params)
rr_clf = RandomForestClassifier(**best_params)
rr_clf.fit(X_train, y_train)
dict_metrics = evaluate_model(rr_clf, X_test, y_test)
return {"clf": rr_clf, "model_metrics": dict_metrics}
Kedro Pipelines
To tie it all together, Kedro uses pipelines. With pipelines, you can set the input and output of the nodes. It also sets the node execution order. It looks very similar to a Directed Acyclic Graph (DAG) in Spark and Airflow. An awesome thing you can do is to create hooks to extend Kedro’s functionality, like adding data validation after node execution and logging model artifacts through MLFlow.
# in <root>/src/<project>/pipelines/data_science/pipeline.py
from kedro.pipeline import node, pipeline
from .nodes import split_data, fit_xgboost
def create_plot_roc_node():
return node(
func=plot_roc,
inputs=["clf", "X_test", "y_test"],
outputs="roc_graph",
name="plot_roc",
)
def create_split_node():
return node(
func=split_data,
inputs=["model_input_table", "params:split_options"],
outputs=["X_train", "X_test", "y_train", "y_test"],
name="split_data_node",
)
def create_xgb_pipeline(**kwargs):
split_node = create_split_node()
plot_node = create_plot_roc_node()
xgb_pipe_instance = pipeline(
[
split_node,
node(
func=fit_xgboost,
inputs=["X_train", "y_train", "X_test", "y_test",
"params:xgboost_params_full_feats"],
outputs={"clf": "clf", "model_metrics": "model_metrics"},
name="train_xgboost",
),
plot_node
],
)
return pipeline(
pipe=xgb_pipe_instance,
inputs="model_input_table",
namespace="xgboost_pipe",
parameters={"params:xgboost_params_full_feats"})
- Line 32 has all the inputs from the split node, but there’s a special parameters dictionary. Kedro automatically puts in your parameters from your
parameters.yml, with the default in yourconf/basedirectory. - Line 34 receives multiple outputs from the nodes. The first is a classifier and the second are model metrics to be saved in MLFlow. It is specified in the
catalog.yaml. Note that Kedro has its own experiments tracking functionality as well, but I want to show you that it does play nice with other tools. - Line 45 receives a set of parameters from parameters.yaml. You can reuse the same pipeline and input several sets of parameters for different runs!
Finally, the top-level of a Kedro project is the pipelines registry, which contains the available pipelines. I define here multiple pipelines and their aliases. The default, __default__ will call all pipelines. You can invoke a particular pipeline through kedro run --pipeline=<name>.
# in <root>/src/<project>/pipeline_registry.py
def register_pipelines() -> Dict[str, Pipeline]:
data_engineering_pipeline = de.create_pipeline()
xgb_pipe = ds.create_xgb_pipeline()
rr_pipe = ds.create_rr_pipeline()
logres_pipe = ds.create_logres_pipeline()
rr_ho_pipe = ds.create_rr_ho_pipeline()
return {
"de": data_engineering_pipeline,
"xgb_pipe": xgb_pipe,
"rr_pipe": rr_pipe,
"rr_ho_pipe" : rr_ho_pipe,
"logres_pipe": logres_pipe,
"__default__": data_engineering_pipeline + xgb_pipe + rr_pipe + logres_pipe + rr_ho_pipe,
}
Afterwards, it’s time for deployment. From here on, you can do several things, as linked here:
- To package and create wheel files, do a
kedro package. The files can then go to your own Nexus or a self-hosted pypi. Even better if you put the package script as part of your build routine in your CI server. Nothing says job done as having another teammate simply do a pip install of your own project! - You can also generate your project documentation using
kedro build-docs. It will create the HTML documentation using Sphinx, so it includes your docstrings. Time to spice up your docs game! - Export your pipelines as docker containers. This can then be part of your organization’s larger orchestration framework. It also helps that the community already has plugins for Kubeflow and Kubernetes.
- Integrate with Airflow and convert your project as an Airflow DAG.
- And a dozen other specific deployments!
MLOps, Kedro and more
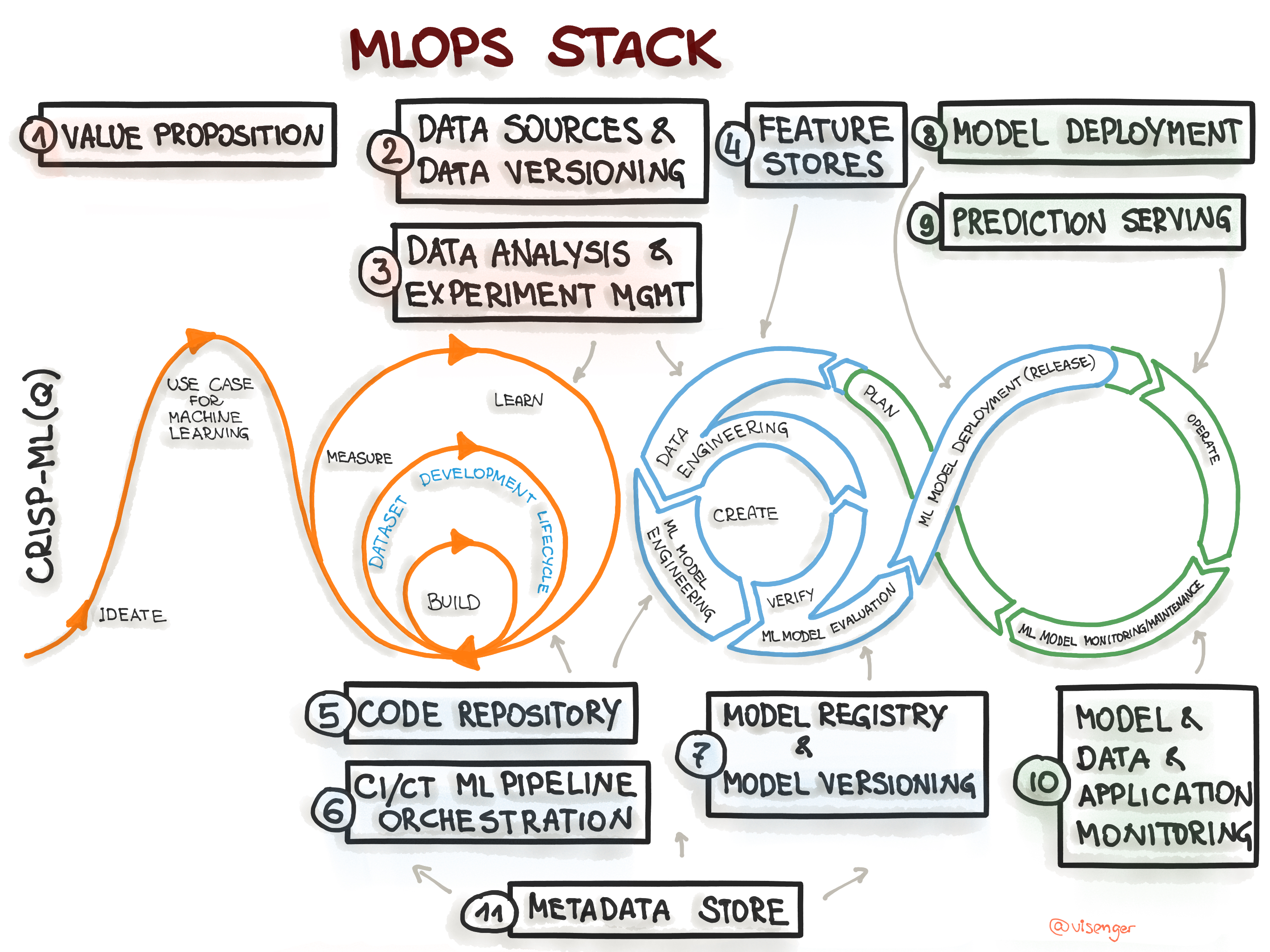
Recall that we have set out to do MLOps, which is simply a sustainable way to rein in the massive complexity that is machine learning. We have achieved a common structure, a way to reproduce runs, track experiments, and deploy to different environments. This is just the beginning, however. Other best practices are converging and quickly evolving. So be sure to practice the fundamentals, and always remember to innovate sustainably.

One reply on “Level Up Your MLOps Journey with Kedro”
[…] In my previous post, I introduced MLOps and how Kedro can be your framework of choice in implementing modular, maintainable, and reproducible pipelines. Recommenders benefit from MLOps since there is a need for rapid experimentation, continuous retraining, and deployment of the models. Successful companies even use advanced A/B testing techniques to deploy several models at once (see Netflix Experimentation Platform). So I think it will be exciting to share my experience in bringing to life a recommender system from engineering, training, and all the way to serving. […]
LikeLike