
Recommendation systems are integral to the modern Internet. There is no way a customer can enjoy their digital experience without your service personalized to them in some way. There is even the rise of the term ‘hyper-personalization’, which is the advanced capability of AI to provide the most relevant items for users by utilizing our ‘digital breadcrumbs’. In technical speak, this is feeding various datasets (clickstream, ratings, text, images, the item itself, etc) to machine learning algorithms in the nearest real-time as possible to offer a dynamic recommendation experience.
In my previous post, I introduced MLOps and how Kedro can be your framework of choice in implementing modular, maintainable, and reproducible pipelines. Recommenders benefit from MLOps since there is a need for rapid experimentation, continuous retraining, and deployment of the models. Successful companies even use advanced A/B testing techniques to deploy several models at once (see Netflix Experimentation Platform). So I think it will be exciting to share my experience in bringing to life a recommender system from engineering, training, and all the way to serving.
To navigate:
To demo the workflow, I will be using MovieLens 10M, a modest-sized dataset in the recommender sense. It’s also rather dense, as interaction data goes, but it’s a good exercise. Also, it contains tags, which can be used as item features. The end-to-end process is unique in that it isn’t just serving a scikit-learn model from MLFlow. There are some customizations to do. But before that, let’s begin with the user API requirements.
Note that I am assuming that the reader is already familiar with collaborative filtering, and nearest neighbor indexing.
If you’d like to skip everything instead, head on over here for my code.
The User API
We will handle two cases, the incoming user is already part of the system (known user), and the incoming user is unknown (cold-start). We’ll go a bit unique and simulate the case where our API responds to a live browsing session. Hence, we will be receiving item ids that correspond to what they have browsed in the previous hour or so.
- Known User Case
- Our user is already logged in and has browsed several items.
- We want to recommend the closest items to what the user browsed.
- Our API receives user ids and item id pairs
- Cold-Start Case
- It’s our first time seeing this user (or he has not logged in)
- Same as with the above, we recommend the closest items
- Our API receives only item ids
We can also have a third case, where we receive only user ids. We can serve the candidates generated from training. That’s a good exercise for the reader to implement!
Workflow Overview
Kedro is used as our workflow framework. Algorithm-wise, we will use LightFM and WARP loss. We will use the generated item embeddings to produce our closest items. We use Optuna for hyperparameter optimization. To create a fast indexing service, we use ANNOY to build our approximate nearest neighbor index. Finally, we use MLFlow to track experiments, store artifacts, and serve our model. To integrate to Kedro, we use kedro-mlflow.
The following diagram illustrates the workflow. This is simple, as Netflix-scale systems can be rather daunting! This is generated from kedro-viz. The green boxes are my pasted-on comments.

Prep Ratings & Prep Item Features
I convert the ratings and item features from pandas DataFrame format to a sparse format. The user & item ID mapping to their location index is stored (‘cid’ are item ids and ‘rid’ are user ids). The default ranking and names mapping are also stored. Visualizing this phase:

In Kedro’s catalog.yaml, I’ve defined all the mappings (dict types) as pickled objects. The ranking is a CSV file.
Factorization
Following the data engineering phase, we train our model. We split our data into training and testing and run LightFM. We then produce our embeddings, biases, and model metrics. Lastly, we sample recommendations. In a real-world scenario, we can also include here some sanity checks and visualizations to automate as much as we can.

As mentioned earlier, Optuna is used for hyperparameter optimization. To integrate to MLFlow, we use callbacks. This actually results in a new MLFlow experiment, different from the created experiment by kedro-mlflow. The original experiment, however, will store the best model’s parameters, plus all the artifacts to be shown later.
Indexing
Our final phase is to index our nearest neighbors using the item factors. This will ensure a quick way to serve our queried items. In the workflow below, validate_index is our node to immediately test our created index in the training process.

This is where we have our first Kedro customization. The objects from the ANNOY library cannot be pickled so we need to customize the loading and saving functionality for the Data Catalog. We implement Kedro’s AbstractDataset and use it like the following.
Upload to MLFlow
If we get everything right, then we upload to MLFlow every artifact we generated since it will be used for model serving. To keep things simple, we will stay within the local filesystem. We use MlflowModelLoggerDataSet to save the artifacts for us, and we define another custom class, KedroMLFlowLightFM, under the MLFlow standard. This will define how MLFlow will load the model and process the input.
Several things happen here. In the first snippet, we define the files uploaded to the MLFlow artifact repository. It looks very ugly since it’s full of temporary files as a staging area for the upload process. I would be very interested to know if you have a better way for this. Next, in the second snippet, we define KedroMLFlowLightFM. This will tell how MLFlow will store and serve the model. This is very important since this will determine how mlflow model serve will work.
Running the Pipeline
Now that key components of the pipeline are complete, let’s run it. Some things to note here:
- Prep features – we’re running a very small subset of MovieLens10M here. This is for a fast cycle time in this demo.
- Training – we’re using Optuna to optimize the dimensionality of the embeddings.
- Indexing – the return value is of type
KedroAnnoyIndex. - Sample recommendations – some fun things to see here.
- At first glance, Shrek shouldn’t be close to the Dark Knight (widely separate genres), but both are mainstream blockbusters, so the algorithm might have picked up on that.
- Included in the nearest neighbors of Ratatouille are other animated films like Monsters Inc, and even international titles like My Neighbor Totoro.
- Rashomon is a timeless film, and it’s cool to see that it’s close to vintage films (Maltese Falcon, Big Sleep) and other cerebral films (Lost Highway, The Name of The Rose).
> kedro run
-- a lot of things get logged here and I'll reduce it to key things
-- (1) Prep Features
Running node: prep_ratings: prep_sparse_ratings([ratings,params:preprocessing]) -> [interactions,rid_to_idx,idx_to_rid,cid_to_idx,idx_to_cid]
Number of users: 5387
Number of items: 2620
Number of rows: (195359, 4)
Sparsity: 0.013841563730609597
-- (2) Training
kedro.pipeline.node - INFO - Running node: factorize: factorize_optimize([train,test,eval_train,sp_item_feats,params:model]) -> [user_factors,item_factors,user_biases,item_biases,model_metrics]
Train: 0.20478932559490204, Test: 0.1860404759645462
Train: 0.24299238622188568, Test: 0.21084092557430267
Train: 0.2665676772594452, Test: 0.22465194761753082
Train: 0.28074997663497925, Test: 0.23137184977531433
Train: 0.2892519235610962, Test: 0.23690366744995117
Train: 0.2953035533428192, Test: 0.2383144646883011
Train: 0.3050306737422943, Test: 0.24187859892845154
Train: 0.3089289367198944, Test: 0.24299241602420807
Train: 0.3151661455631256, Test: 0.2450343668460846
Train: 0.3220716714859009, Test: 0.24473735690116882
Trial 0 finished with value: 0.24800445139408112 and parameters: {'n_components': 59}. Best is trial 0 with value: 0.24800445139408112
-- (3) Indexing
Running node: build_index: build_index([item_factors,params:index_params]) -> [kedro_annoy_dataset]
Running node: validate_index:
-- (4) Sampling indexing results (recommendations)
validate_index([kedro_annoy_dataset,idx_to_names]) -> [validated_kedro_annoy_dataset]
Closest to Dark Knight, The (2008) :
Dark Knight, The (2008)
Sin City (2005)
Shrek 2 (2004)
Kill Bill: Vol. 1 (2003)
Batman Begins (2005)
Princess Mononoke (Mononoke-hime) (1997)
Ratatouille (2007)
Harry Potter and the Order of the Phoenix (2007)
Scarface (1983)
Lord of the Rings: The Fellowship of the Ring, The (2001)
Closest to Ratatouille (2007) :
Ratatouille (2007)
Monsters, Inc. (2001)
My Neighbor Totoro (Tonari no Totoro) (1988)
Kiki's Delivery Service (Majo no takkyûbin) (1989)
Spirited Away (Sen to Chihiro no kamikakushi) (2001)
Who Framed Roger Rabbit? (1988)
WALL·E (2008)
Cars (2006)
Howl's Moving Castle (Hauru no ugoku shiro) (2004)
Shrek (2001)
Closest to Rashomon (Rashômon) (1950) :
Rashomon (Rashômon) (1950)
Maltese Falcon, The (a.k.a. Dangerous Female) (1931)
Lost Highway (1997)
Big Sleep, The (1946)
Name of the Rose, The (Der Name der Rose) (1986)
Fanny and Alexander (Fanny och Alexander) (1982)
Brick (2005)
Dogville (2003)
Vertigo (1958)
Nine Queens (Nueve Reinas) (2000)If everything went well, then we should have the following in our MLFlow experiment.
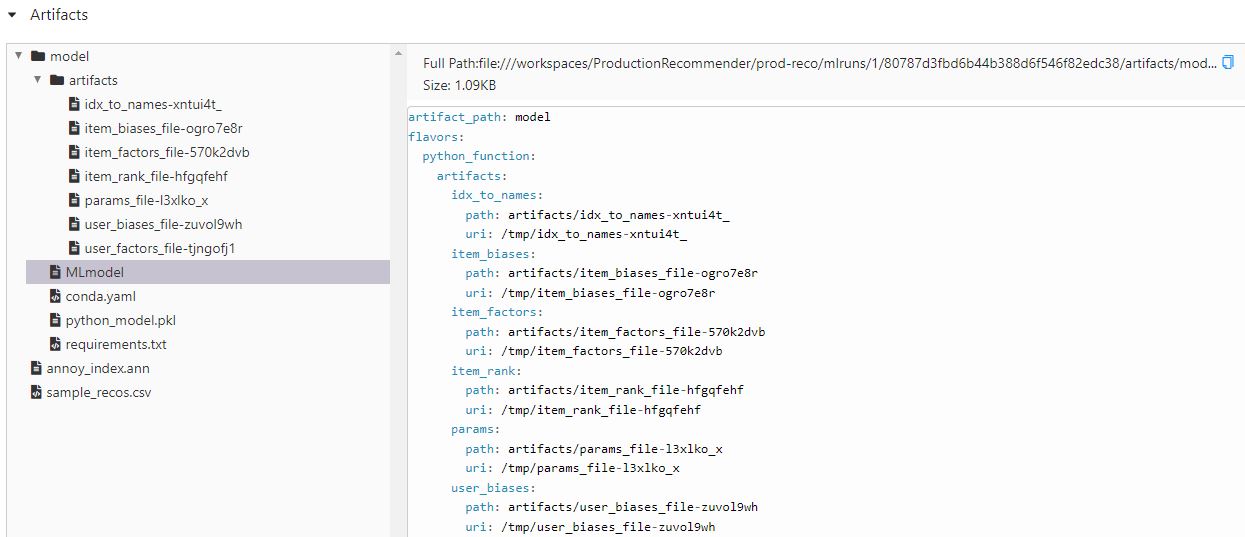
Serving (and Testing!)
To serve the model, we will package our project, then use MLFlow to deploy an API for us. The build and deploy script is as follows. As always, we’ll keep things local.
-- our project is named prod-reco
> kedro package
-- in case we have installed our module already
> pip uninstall prod-reco -y
-- install locally
> pip install src/dist/prod_reco-0.1-py3-none-any.whl
-- mlflow serve. You can use the ff way, or the model registry
mlflow models serve -m "runs:/<run-id>/model" -p 5001 --no-condaFor the above, I used the run-id of the experiment, but using the Model Registry instead is fine. Also, –no-conda is used since I’ve installed the package locally only.
Now, to test our API, we use pytest. We call our API in different ways and see if it runs correctly. If successful, you should have the output below.
> pytest --no-cov -s src/tests/test_endpoint.py::TestEndpoint
==test session starts ==
...
...
...
plugins: mock-1.13.0, cov-3.0.0, anyio-3.5.0
collected 5 items
src/tests/test_endpoint.py
Dark Knight
["City of God (Cidade de Deus) (2002)", "Dark Knight, The (2008)", "History of Violence, A (2005)", "3:10 to Yuma (2007)", "Animatrix, The (2003)"]
.
Dark Knight & Kung Fu Panda
["Wallace & Gromit: The Wrong Trousers (1993)", "Monsters, Inc. (2001)", "City of God (Cidade de Deus) (2002)", "Dark Knight, The (2008)", "Mulan (1998)", "Ratatouille (2007)", "History of Violence, A (2005)", "3:10 to Yuma (2007)", "Animatrix, The (2003)", "Kung Fu Panda (2008)"]
.
Dark Knight & Kung Fu Panda & Godfather II
["Godfather, The (1972)", "Godfather: Part II, The (1974)", "Wallace & Gromit: The Wrong Trousers (1993)", "Monsters, Inc. (2001)", "City of God (Cidade de Deus) (2002)", "City of God (Cidade de Deus) (2002)", "Untouchables, The (1987)", "Dark Knight, The (2008)", "Carlito's Way (1993)", "Mulan (1998)"]
.
User likes vintage movies
[{"userId": 2241, "recos": ["Mulan (1998)", "Wallace & Gromit: The Wrong Trousers (1993)", "Ratatouille (2007)", "Monsters, Inc. (2001)", "History of Violence, A (2005)", "Kung Fu Panda (2008)", "3:10 to Yuma (2007)", "Animatrix, The (2003)", "City of God (Cidade de Deus) (2002)", "Dark Knight, The (2008)"]}]
.
First user likes vintage movies, second likes animation
[{"userId": 190, "recos": ["Animatrix, The (2003)", "History of Violence, A (2005)", "Kung Fu Panda (2008)", "3:10 to Yuma (2007)", "Ratatouille (2007)", "City of God (Cidade de Deus) (2002)", "Dark Knight, The (2008)", "Mulan (1998)", "Monsters, Inc. (2001)", "Wallace & Gromit: The Wrong Trousers (1993)"]}, {"userId": 2241, "recos": ["Mulan (1998)", "Wallace & Gromit: The Wrong Trousers (1993)", "Ratatouille (2007)", "Monsters, Inc. (2001)", "History of Violence, A (2005)", "Kung Fu Panda (2008)", "3:10 to Yuma (2007)", "Animatrix, The (2003)", "City of God (Cidade de Deus) (2002)", "Dark Knight, The (2008)"]}]
== 5 passed in 1.40s ==Summary
It took us a lot of time to get the pipeline running, but it is well worth it. We defined our data preparation, training, indexing, serving, and testing. I’d like to stress that at this point, you can do several things rather easily:
- Continuous training – Write a cronjob or convert it to an Airflow DAG using kedro-airflow to make the pipeline run daily. Note that we have tests in place to always check if it works. Batch jobs have never been easier.
- Dockerize your training application – You can integrate the resulting container into your organization’s larger orchestration pipelines with a guarantee that it will work.
- Deploy your serving application – Use MLFlow to create a container from your customized model. Lock and load!
- Change configurations – Want to use cloud resources? It’s just as simple as changing configurations. The codebase will largely be untouched!
Thanks for reading, and good luck in your MLOps journey!

3 replies on “Deploying a Recommendation System the Kedro Way”
Very cool blog post 🙂
LikeLike
Hello! I am Nok from the developer team of Kedro, I found this post quite informative and I would love to add this into our awesome-kedro list. I have created a PR for this, I hope this is fine :). https://github.com/kedro-org/awesome-kedro/pull/4
LikeLike
Hey, thank you very much!
LikeLike